
今週の名言
「幸福になる秘訣は快楽を得ようとひたすらに努力することではなく、努力そのもののうちに快楽を見出すことである。」
アンドレ・ジット
マスタ/ディテール関係の実装を考える
今回は検証の前にデータ構造設計の話をしておきたいと思います。
売上-売上明細のように1対多のカーディナリティを持つ2つのテーブル(正確にはエンティティと表現すべきですが、物理的に実装するところまでを述べるのでテーブルと呼称しつつ、エンティティという表現も適宜使い分けることにします。)のリレーションシップをマスタ/ディテール関係と呼んだりすることがあります。
簡単に言うと「親子関係」であり、ER図(IE表記)で表現すると以下のようになります。(図1)

図1
- 親表(T_PAR)の主キー(PK)はPIDであり、子表(T_CHD)の主キーの一部を成すことで親子関係を表現することができる。
- この図では子表(T_CHD)の主キー(PK)は「PID + CSEQ(連番)」であり、ユニーク(一意)性を担保する必要がある。
- IE表記において、子表を角の丸い四角形で表現した場合、親表に対する「従属エンティティ」あるいは「依存エンティティ」であることを意味する。
- つまり、子表の主キーの一部であるPIDは必ず存在する必要がある。(Not Null制約)
この親子関係は、次のようにも表現することができます。(図2)

図2
- 子表(T_CHD)の主キー(PK)はCIDのみであり、このカラムだけで一意性を担保できる。
- 主キー項目以外に、子表には親表のPID(外部キー、FK)を持つ必要があり、かつこのカラムはNot Nullである必要がある。
- 子表を角がある四角形で表現した場合、「独立エンティティ」あるいは「非依存エンティティ」であることを意味する。
- つまり、PID列がNullであっても子レコードは存在できるが、前述のようにPID列は必ずNot Nullであるので論理的に従属関係にある。
今検証しているIdentity Columnを活用してマスタ/ディテール関係を実装しようとすると、必然的に図2の形になります。
従属的な親子関係を表現するためには必ずしも図1のような「従属エンティティ」を使う必要はないと思います。
子レコードが親レコードに依存しているということと、主キーの一部に親レコードの主キー値を持たなければならないというのは必ずしも同じでないということです。
重要なのは「親レコードを指す主キー値がNullであってはならない。」ということなのです。
親-子-孫関係を考える
図1、図2どちらでもよい、というのはある意味悩ましい事実です。
そこでこの問題をより掘り下げるために、親-子-孫の関係を考えてみましょう。
従属エンティティは先祖をたどることができる
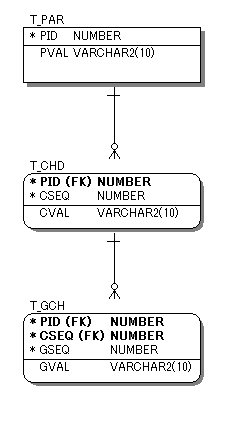
図3
図3を見れば明らかですが、従属エンティティは孫エンティティから先祖である親エンティティを特定することができます。つまり、主キーに「PID」というカラムを持つテーブルは、すべて親エンティティに従属することがわかります。
例えばPID単位でパーティショニングを行うような場合、これは大きなメリットと言えるかもしれません。
ただし、主キーが複数のカラムで構成されるデメリットも当然あります。親エンティティの主キー構成が万一変更されるような場合、従属するすべてのエンティティに影響が及びます。
主キーは本来変更されない前提で設計されるのですが、未来永劫変更されない保証はありません。
また、設計の初期段階で親エンティティの主キー構成がなかなか決まらないと子エンティティの設計もなかなか決まらないという恐れもあります。(こちらの方が多いかもしれません。)
独立エンティティは構造がシンプル

図4
一方、独立エンティティは1つの主キー項目とそれ以外の項目というデータ構造は、親・子・孫で変わることはありません。
主キー項目は文字通りID(IDentity)項目であり、行を一意に識別することができます。そしてOracleデータベースの場合、シーケンス・オブジェクト(Sequence、順序)が生成する重複のない値を使用します。
この図をよく見ると、孫エンティティには親エンティティの主キーであるPIDを保持するカラムがありません。従って自分の先祖を簡単にたどることができません。
しかし、これを単純にデメリットと捉えることは間違いだと思います。実際にクエリを記述する場合、ジョイン(結合)するテーブルは2つだけですので、例えば子と孫テーブルをジョインする場合、その上の親テーブルを意識する必要はありません。ジョインの結果得られた結果セットと親テーブルをジョインするからです。
むしろ孫テーブルにPIDを持つと、親・孫という間違ったジョインを記述してしまう恐れがあります。そのような場合重複行が発生してしまい、無理矢理distinctで重複行を排除するようなことをしてしまうのです。これにより不要なFull Scanが発生するようなこととなり、ミスをミスで隠蔽するという最悪のSQL文を書いてしまっていたというケースをよく見かけます。
従属エンティティのメリットとしてパーティショニングがたやすい、ということを挙げましたが独立エンティティでも工夫次第ではパーティション化をすることができます。これは簡単な発想で解決できますので、是非考えてみてください。
「独立・依存」エンティティをIdentity Columnで実装する
独立した子エンティティでありながら外部キー項目をNot Nullとする設計を「独立・依存エンティティ」と呼びたいと思います。
一概に決め付けることは厳に慎むべきですが、設計時の混乱や運用中の性能問題を数多く見てきた経験から、この「独立・依存エンティティ」の考え方は有効な解決策となり得ると実感しています。
実際にデータ構造のリファクタリングを成功させた例では、この基本的な考え方に沿って設計を進めました。
ID列は複数のカラムからなる主キーとは違い、代替キーとかサロゲートキーと呼ばれます。何が何でもサロゲートキーにしなければならないと主張するつもりはありません。しかし、どんなキーが自然にユニークとなる識別キー(ナチュラルキー)になるかはよく考える必要があります。
私は、世の中の設計における混乱は、識別キーと検索キーを混同していることによることも多いと思います。
。。。
と前置きのつもりで書いていたら長くなってしまいましたので、「独立・依存エンティティ」をIdentity Columnで実装するというテーマの検証は次回に回したいと思います。
結論から言うと、この機能はまだまだイケてないと思うこともあるので、その辺の紹介も含め次回で検証したいと思います。
続く